MapReduce實驗報告


I. 引言
A. 實驗目的
1. 理解MapReduce編程模型的基本原理
2. 學習如何實現簡單的MapReduce作業
3. 分析MapReduce在處理大數據時的性能和效率
B. 實驗背景
1. MapReduce技術的發展歷史
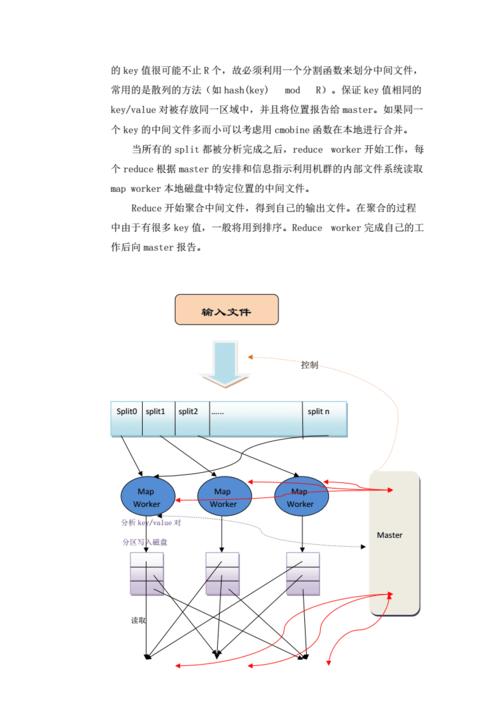
MapReduce由谷歌在2004年提出,作為一種簡化大規模數據處理的軟件框架,它允許開發者編寫能夠處理大量數據的分布式應用程序。
2. MapReduce在數據處理中的應用
MapReduce廣泛應用于搜索引擎索引構建、日志分析、數據挖掘等領域,是大數據處理的關鍵技術之一。
3. 當前大數據處理的趨勢與挑戰
隨著數據量的不斷增長,傳統的數據處理方法已經無法滿足需求,MapReduce作為處理大數據的有效工具,其性能和效率成為了研究的熱點。
II. 實驗環境與工具
A. 硬件環境

描述實驗室提供的服務器配置,包括CPU型號、內存大小、硬盤容量等。
B. 軟件環境
1. 操作系統
列出實驗中使用的操作系統版本,如Linux發行版。
2. 編程語言
說明使用的編程語言,如Java。
3. MapReduce框架
介紹使用的MapReduce框架,如Apache Hadoop或Apache Spark。
C. 輔助工具
描述用于監控和分析MapReduce作業性能的工具,如Hadoop的Web界面或第三方工具。
III. 實驗步驟
A. 數據準備
1. 數據來源
說明數據的來源,如公開數據集或實驗室提供的數據。
2. 數據預處理
描述對原始數據進行的清洗和格式化操作。
B. MapReduce作業設計
1. 映射階段(Map)
詳細說明映射階段的函數設計和邏輯。
2. 規約階段(Reduce)
詳細說明規約階段的函數設計和邏輯。
C. 實驗執行
1. 作業提交
描述如何提交MapReduce作業到集群。
2. 運行監控
解釋如何監控作業的運行狀態和性能指標。
3. 結果收集
說明如何收集作業的輸出結果。
IV. 實驗結果與分析
A. 性能評估
1. 運行時間
展示作業的運行時間,并與預期進行比較。
2. 資源消耗
分析作業運行時的資源消耗,如CPU使用率、內存占用等。
3. 錯誤分析
記錄并分析作業運行過程中遇到的任何錯誤或異常。
B. 結果展示
1. 輸出數據
展示MapReduce作業的輸出數據樣本。
2. 數據對比
如果可能,與非MapReduce方法的結果進行對比。
C. 問題與解決方案
討論在實驗過程中遇到的問題及其解決方案。
V. 討論
A. MapReduce模型的優勢與局限性
分析MapReduce模型在處理大數據時的優勢和可能遇到的局限性。
B. 實驗中學到的經驗與教訓
分享實驗過程中學到的經驗和應該注意的問題。
C. 對未來工作的展望
提出對未來MapReduce技術發展的預測和建議。
VI. 上文歸納
A. 實驗歸納
歸納實驗的主要發現和學習成果。
B. 實驗的意義與應用前景
討論實驗結果對實際應用和未來研究的意義。
VII. 參考文獻
列出實驗報告中引用的所有文獻和資料來源。
VIII. 附錄
A. 代碼清單
提供完整的MapReduce作業代碼。
B. 數據樣本
附上實驗中使用的數據樣本。
C. 圖表與圖像
包括實驗結果的圖表和圖像,以便更直觀地展示分析結果。