MapReduce是一種編程模型,用于處理和生成大數據集。它分為兩個階段:Map階段,將輸入數據分成多個部分并分別處理;Reduce階段,將Map階段的輸出合并以得到最終結果。


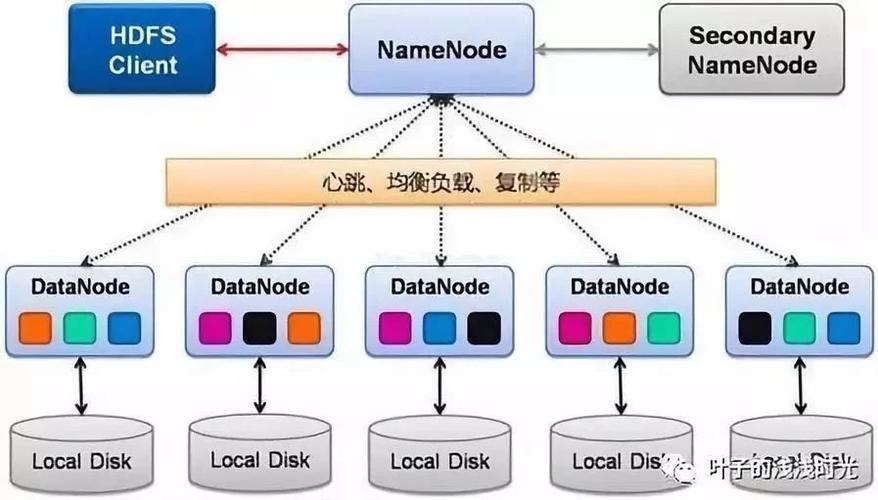
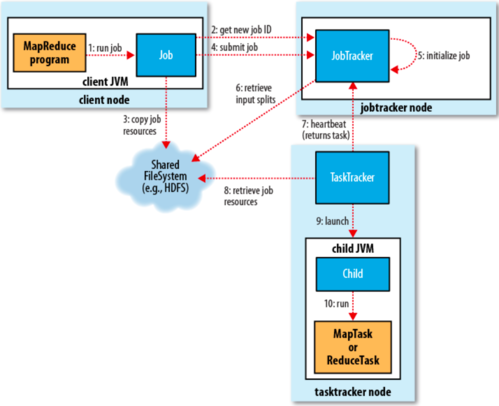
MapReduce是一種編程模型,用于處理和生成大數據集的并行算法,它由兩個主要階段組成:Map階段和Reduce階段,在Map階段,輸入數據被分割成多個獨立的塊,然后每個塊被映射到一個鍵值對,在Reduce階段,所有具有相同鍵的值被組合在一起,并應用一個規約函數以生成最終結果。
以下是一個簡單的MapReduce示例,用于計算文本中單詞的出現次數:
1、Map階段:
輸入:文本文件("hello world hello mapreduce")
輸出:鍵值對列表([("hello", 1), ("world", 1), ("hello", 1), ("mapreduce", 1)])
2、Reduce階段:
輸入:來自Map階段的鍵值對列表
輸出:單詞及其出現次數的列表([("hello", 2), ("world", 1), ("mapreduce", 1)])
以下是一個使用Python編寫的簡單MapReduce實現:
from collections import defaultdict
import itertools
def map_function(text):
words = text.split()
return [(word, 1) for word in words]
def reduce_function(word_counts):
result = defaultdict(int)
for word, count in word_counts:
result[word] += count
return list(result.items())
示例輸入
input_text = "hello world hello mapreduce"
Map階段
mapped_data = map_function(input_text)
print("Mapped data:", mapped_data)
Reduce階段
reduced_data = reduce_function(mapped_data)
print("Reduced data:", reduced_data)
在這個例子中,map_function將輸入文本分割成單詞,并為每個單詞生成一個鍵值對(單詞,1)。reduce_function接收這些鍵值對,并將具有相同鍵的值相加,從而得到每個單詞的出現次數。
聲明:所有內容來自互聯網搜索結果,不保證100%準確性,僅供參考。如若本站內容侵犯了原著者的合法權益,可聯系我們進行處理。