
AIxiv專欄是本站發布學術、技術內容的欄目。過去數年,本站AIxiv專欄接收報道了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯系報道。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
論文:https://arxiv.org/pdf/2408.08067 項目地址:https://github.com/amazon-science/RAGChecker
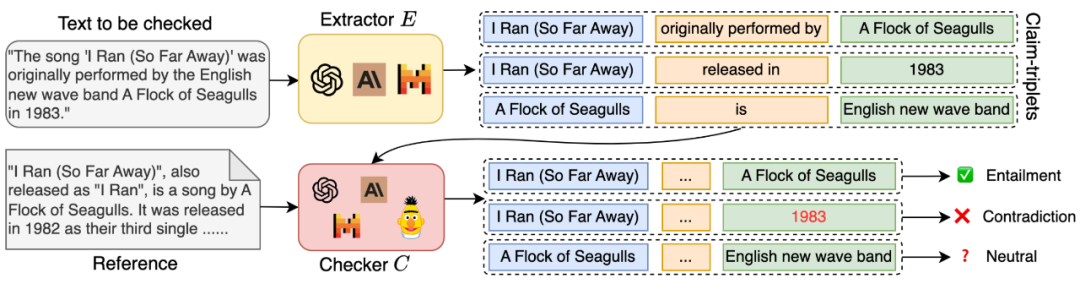
細粒度評估:RAGChecker 采用基于聲明(claim)級別的蘊含關系檢查,而非簡單的回復級別評估。這種方法能夠對系統性能進行更加詳細和微妙的分析,提供深入的洞察。 全面的指標體系:該框架提供了一套涵蓋 RAG 系統各個方面性能的指標,包括忠實度(faithfulness)、上下文利用率(context utilization)、噪聲敏感度(noise sensitivity)和幻覺(hallucination)等。 經過驗證的有效性:可靠性測試表明,RAGChecker 的評估結果與人類判斷有很強的相關性,其表現超過了其他現有的評估指標。這保證了評估結果的可信度和實用性。 可操作的洞察:RAGChecker 提供的診斷指標為改進 RAG 系統提供了明確的方向指導。這些洞察能夠幫助研究人員和實踐者開發出更加有效和可靠的 AI 應用。
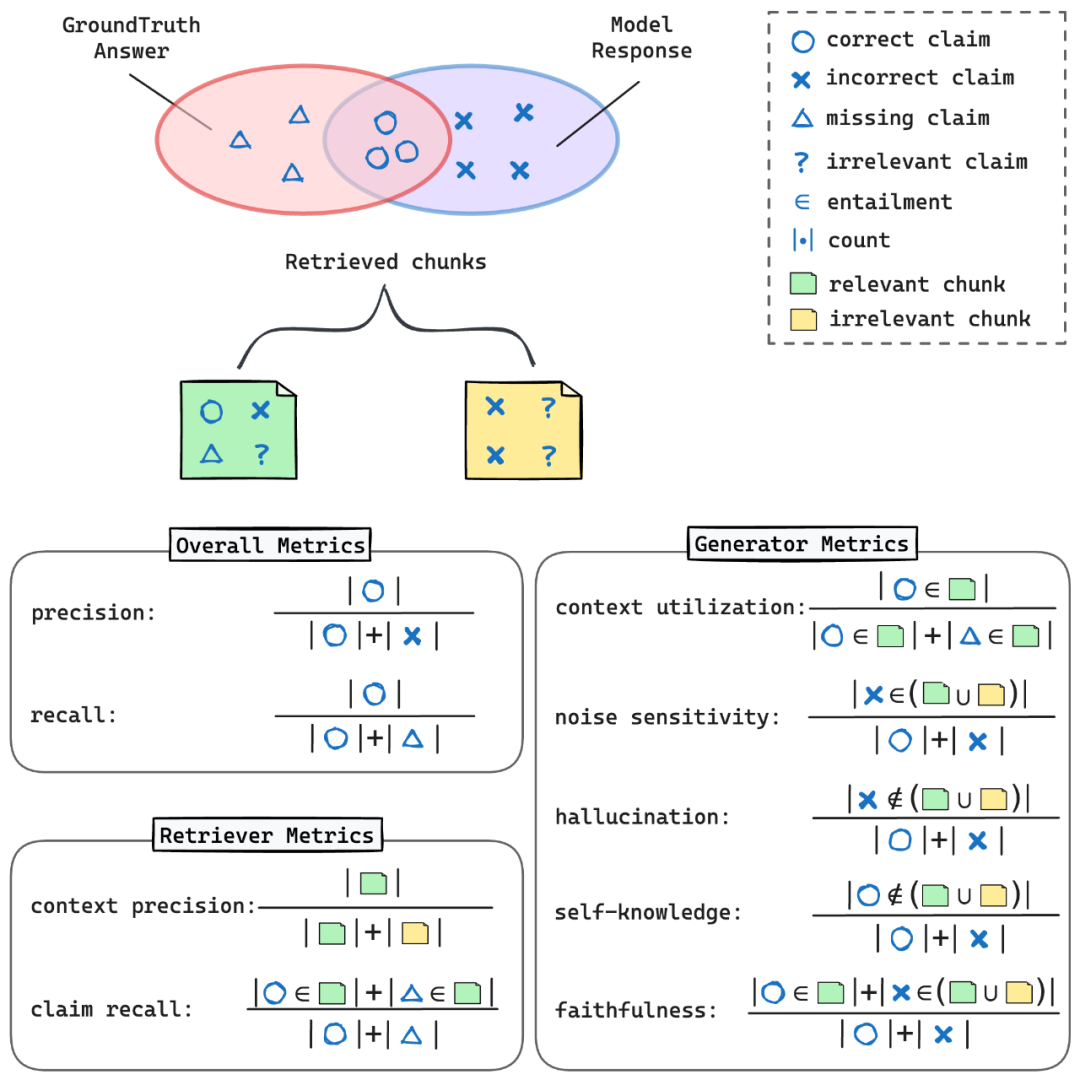
Precision(精確率):模型回答中正確陳述的比例 Recall(召回率):模型回答中包含的標準答案中陳述的比例 F1 score(F1 分數):精確率和召回率的調和平均數,提供平衡的性能度量
Context Precision(上下文精確率):在所有檢索塊中,包含至少一個標準答案陳述的塊的比例 Claim Recall(陳述召回率):被檢索塊覆蓋的標準答案陳述的比例
Context Utilization(上下文利用率):評估生成模塊如何有效利用從檢索塊中獲取的相關信息來產生正確的陳述。這個指標反映了系統對檢索到的信息的利用效率。 Noise Sensitivity(噪音敏感度):衡量生成模塊在回答中包含來自檢索塊的錯誤信息的傾向。這個指標幫助識別系統對不相關或錯誤信息的敏感程度。 Hallucination(幻覺):測量模型生成既不存在于檢索塊也不在標準答案中的信息的頻率。這就像是捕捉模型 “憑空捏造” 信息的情況,是評估模型可靠性的重要指標。 Self-knowledge(模型內部知識):評估模型在未從檢索塊獲得信息的情況下,正確回答問題的頻率。這反映了模型在需要時利用自身內置知識的能力。 Faithfulness(忠實度):衡量生成模塊的響應與檢索塊提供的信息的一致程度。這個指標反映了系統對給定信息的依從性。
pip install ragcheckerpython -m spacy download en_core_web_sm
關注:愛掏網
{ "results": [ { "query_id": "< 查詢 ID>", "query": "< 輸入查詢 >", "gt_answer": "< 標準答案 >", "response": "<RAG 系統生成的回答 >", "retrieved_context": [ { "doc_id": "< 文檔 ID>", "text": "< 檢索塊的內容 >" }, ... ] }, ... ]? ?}
關注:愛掏網
使用命令行:
ragchecker-cli \--input_path=examples/checking_inputs.json \--output_path=examples/checking_outputs.json
關注:愛掏網
或者使用 Python 代碼:
from ragchecker import RAGResults, RAGCheckerfrom ragchecker.metrics import all_metrics# 從 JSON 初始化 RAGResultswith open ("examples/checking_inputs.json") as fp:rag_results = RAGResults.from_json (fp.read ())# 設置評估器evaluator = RAGChecker ()# 評估結果evaluator.evaluate (rag_results, all_metrics)print (rag_results)
關注:愛掏網

較低的 Claim Recall(陳述召回率)可能表明需要改進檢索策略。這意味著系統可能沒有檢索到足夠多的相關信息,需要優化檢索算法或擴展知識庫。 較高的 Noise Sensitivity(噪音敏感度)表明生成模塊需要提升其推理能力,以便更好地從檢索到的上下文中區分相關信息和不相關或錯誤的細節。這可能需要改進模型的訓練方法或增強其對上下文的理解能力。 高 Hallucination(幻覺)分數可能指出需要更好地將生成模塊與檢索到的上下文結合。這可能涉及改進模型對檢索信息的利用方式,或增強其對事實的忠實度。 Context Utilization(上下文利用率)和 Self-knowledge(模型內部知識)之間的平衡可以幫助你優化檢索信息利用和模型固有知識之間的權衡。這可能涉及調整模型對檢索信息的依賴程度,或改進其綜合利用多種信息源的能力。
以上就是給RAG系統做一次全面「體檢」,亞馬遜開源RAGChecker診斷工具的詳細內容,更多請關注愛掏網 - it200.com其它相關文章!
聲明:所有內容來自互聯網搜索結果,不保證100%準確性,僅供參考。如若本站內容侵犯了原著者的合法權益,可聯系我們進行處理。